
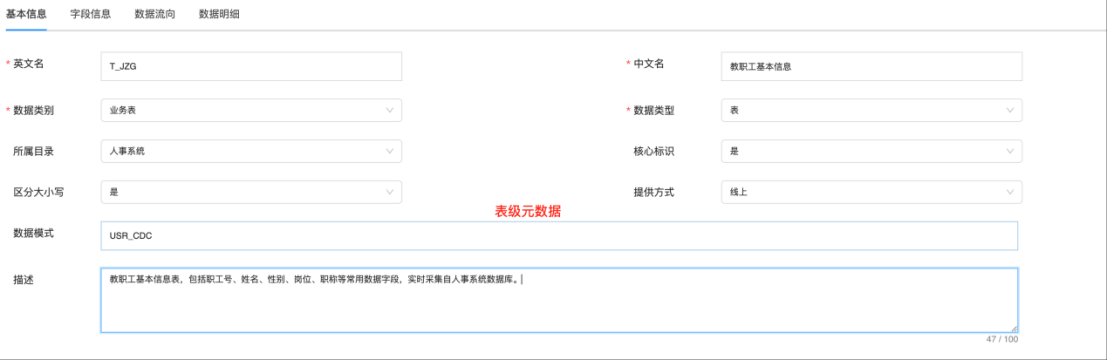
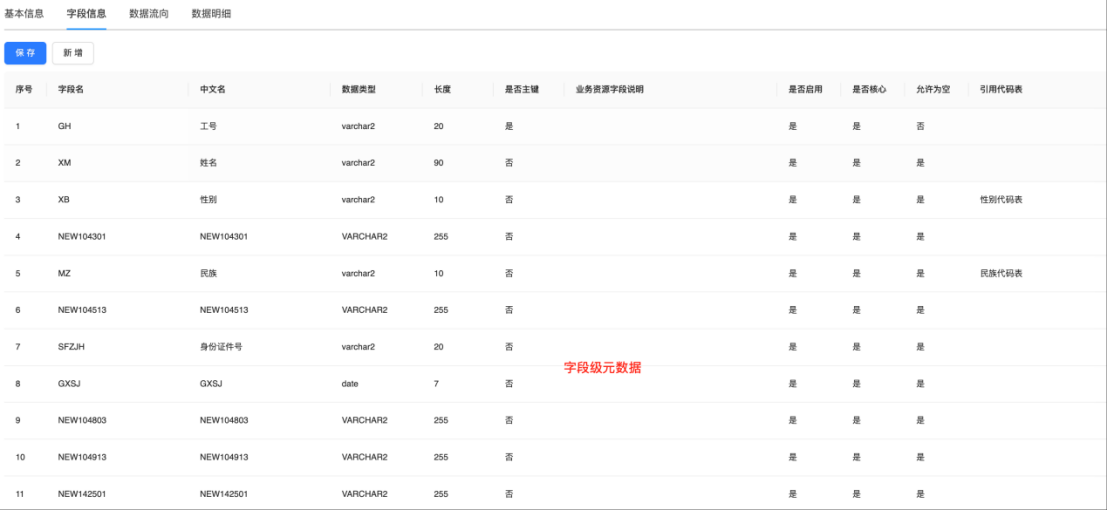
语义识别是数据治理的第一步,在完成源端数据接入之后,需要对数据完成元数据语义的识别和备注,包括技术元数据、业务元数据、管理元数据、操作元数据及元数据血缘等信息。在传统实施过程中,业务数据集成后需要耗费大量人工对数据进行中文语义的标注,机械且繁琐,效率低下。



为解决这一难题,迪塔维V5解决方案采用了一体化递进式的智能识别智能体,基于文档结构特征和智能语义解析的自由模型,完成对各类PDF、Word字典表的结构化提取并完成自动化注释工作,在此基础上,结合迪塔维十余年实施经验积累的云端知识库进一步补全和标注未匹配到的数据语义信息,极大地提升了数据标注的效率。

图:一键智能语义识别
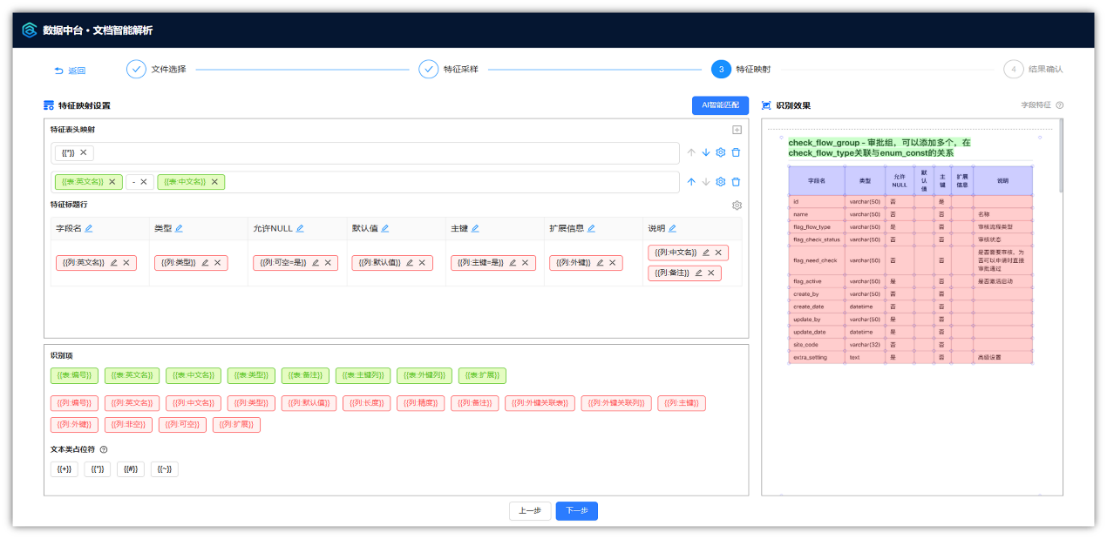
图:数据字典文档特征映射

图:在没有任何资料支撑的情况下,可选用AI自主识别
经过不断的测试验证,智能化提取能够做到数据无遗漏,且自动注释的准确率超过95%,经人工检测确认后完成标注过程,平均每个业务系统可以节省约1人周的工作时间!
在高校日常工作中,经常会遇到大量重复的文档系统录入工作,如:将Excel表格和Word表单进行填报收集后录入数据中台或业务系统,数据收集后需要相关人员耗费大量时间进行数据归档。为解决这一问题,我们把智能语义和文件特征识别的能力包装成文档结构化提取智能体,内置在中台之中,智能体能够深度理解文档中的文本语义,包括词汇含义、句子结构、上下文逻辑等,从而准确判断哪些是需要提取的关键信息,自动化实现数据的统一提取和结构化转换工作。
文档识别智能体可面向各类文档数据的结构化集成场景,支持字典文档、表格、多行文本、表单多种文档类型,支持word、pdf、Markdown等多种文件格式,经过不断打磨验证,解决了跨页断行、跨页断表、水印干扰、混合布局、父子表复杂嵌套等疑难杂症,完美实现了文档智能化集成的“近人化”能力跃升。

图:随机表格自动化提取为结构数据
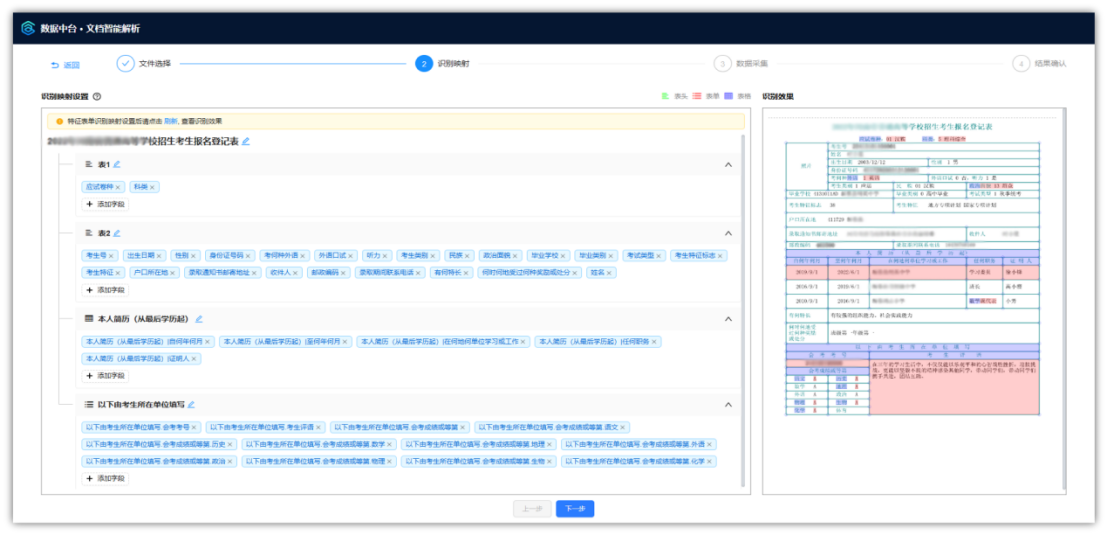
图:各类复杂表单自动提取为多表结构数据
在某客户现场,我们基于文档识别智能体,成功解决了各类人员情况一览表的数据批量采集问题,系统自动针对PDF复杂报表提取人员姓名、编号、科研信息、教学信息、个人建立等各类信息,将其映射为模型表和字段,自动建表后完成批量化、自动化的数据采集过程。

图:专技人员情况一览表原稿

图:数据识别采集后结果确认
AI与数据治理的结合将作为可信数据空间V5解决方案的领航灯塔,引领数据治理从“人治”向“智治”的变革式发展。作为一家面向高校提供专业数据治理与应用解决方案的公司,我们始终坚信先进的技术和优质的服务会赢得客户的信任与支持。当下与未来,V5解决方案会疏通更多数据治理的痛点、难点、堵点,加速提升数据治理与应用落地的效率和自动化水平,更多场景,敬请期待——