
“五步、双线、十环”是迪塔维始终贯彻的数据治理实施方法论,“当AI遇上数据治理”第一期给大家介绍了智能语义识别和非结构文档的智能化集成能力,实现了在“摸家底”步骤中数据调研和识别的自动化辅助。本期迪小数将继续为您带来V5方案系列介绍——智能定标建模和代码对标转标的自动化能力,助力“定标准”步骤的科学、高效落地,让AI辅助实现“快速定标、精准转码、提效减负”!
智能定标建模,让规范落地更高效!
数据标准作为数据采集、存储、共享和应用的基础,为数据治理各个环节提供统一的信息规范,是高校数字化建设的重要基础工作之一。广义的数据标准涵盖了元数据标准、数据分类标准、数据编码标准、数据元素标准、统一代码标准、数据交换技术规范等,上述内容在迪塔维数据中台产品中都有明确的管理口径。传统数据定标工作需要人工参考各类国标、部标及业务上报标准,再结合学校的实际情况,从庞杂的数据中逐条梳理出数据类型、指标定义、格式要求等,不仅占用大量工作时间,还可能出现关键信息遗漏等问题,影响后续治理工作。
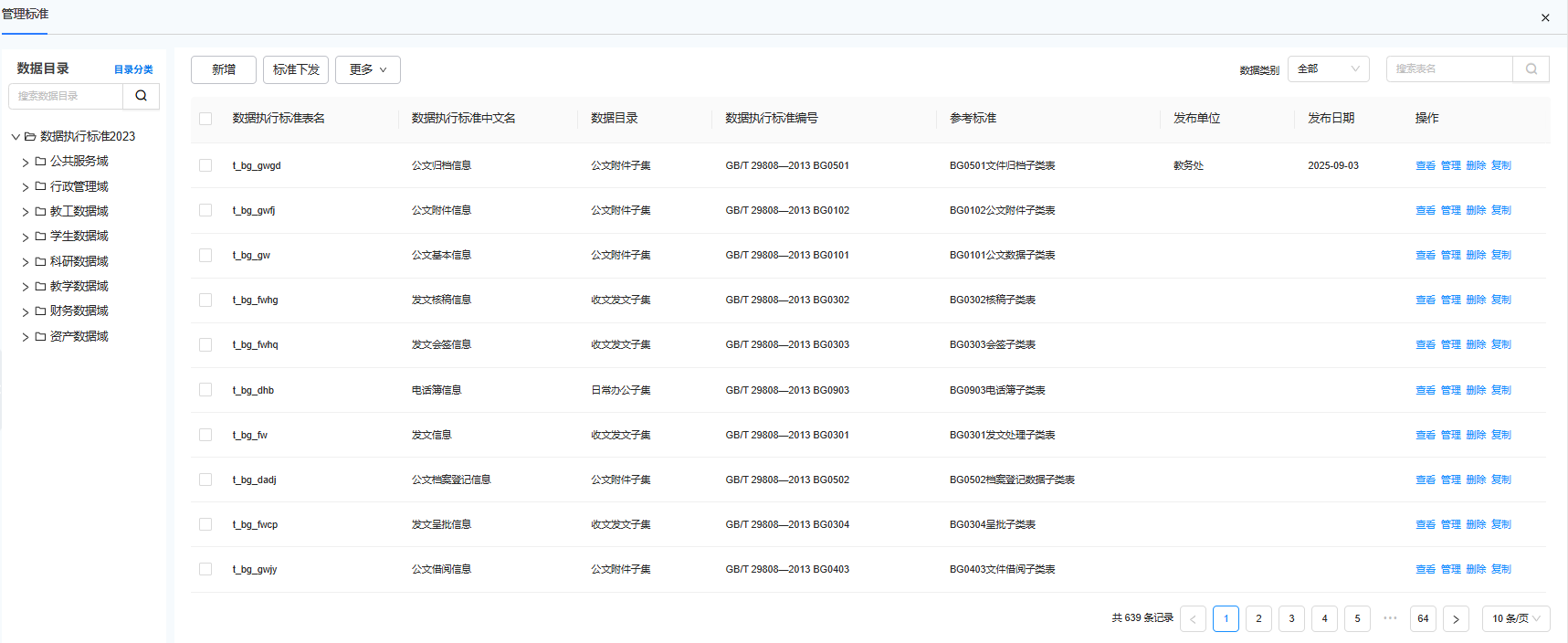

图1 数据执行标准规范
迪塔维V5解决方案中的定标智能体以教育部发布的多项数据规范、建设标准为基线,结合学校自身业务特征,通过标准特征分析,建立数据体系间的逻辑关系,形成符合国家要求和学校自身特性的执行标准“规范库”。
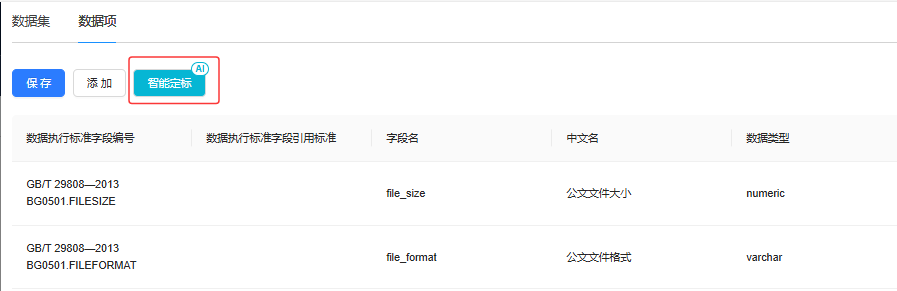

图2 智能定标
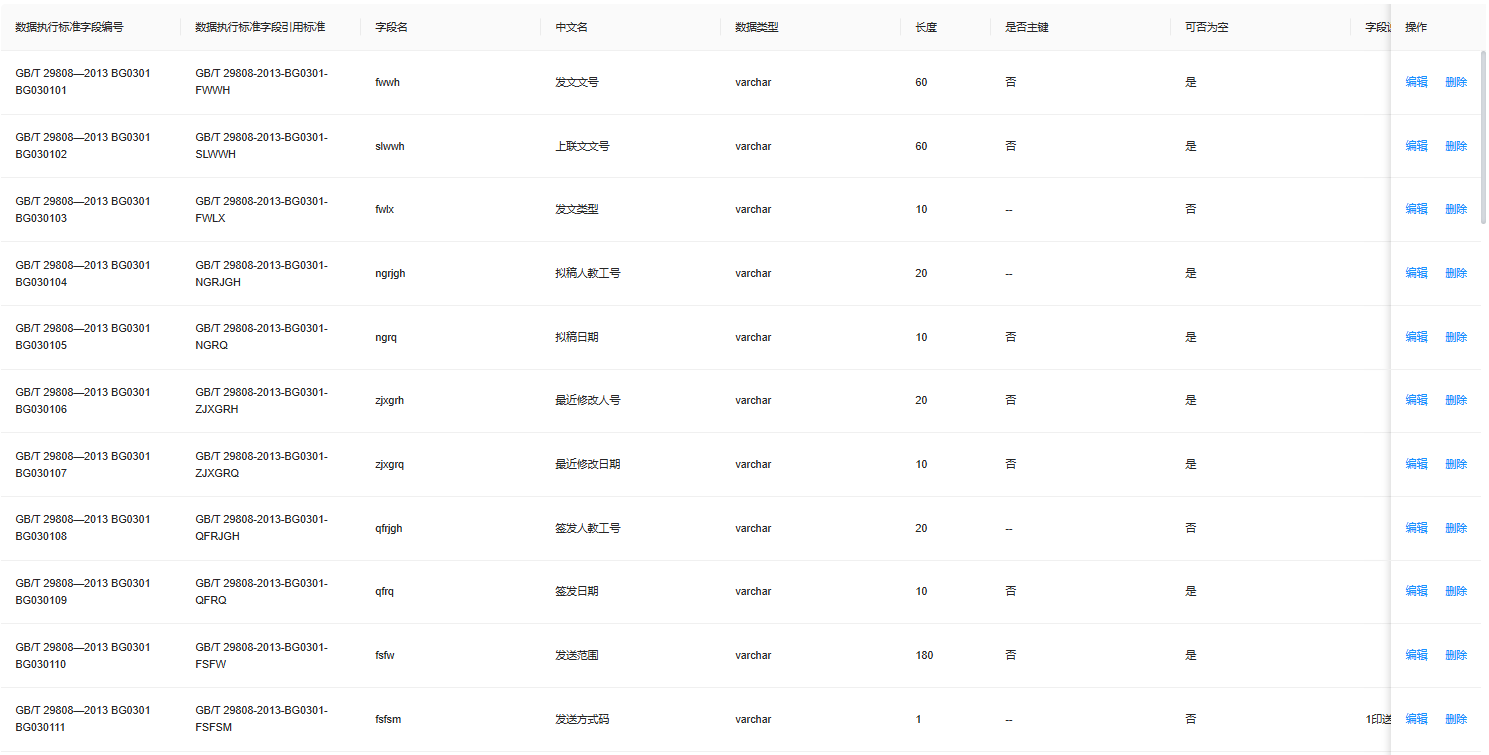
图3 智能定标结果呈现
采用智能定标的方式可以将定标环节从传统的“部门访谈、数据调研、标准梳理、方案评审”数月级的时间跨度缩短至数日,在保证定标结果准确性和落地效果的基础上,大幅降低了人工成本和时间成本!
智能对标转码,告别“人工对标”,让数据流通更顺畅!
数据治理的核心目标之一是建设数据仓库、汇聚全量数据,而高校的数据通常分散在人事、学工、教务、科研、财务等多个业务系统中,因此数据采集时需要将“代码标准”作为系统间互认的核心“语言”。但在实际建设过程中,往往会出现由代码不一致引起的数据整合失效、数据质量降低、业务流程卡顿、管理决策失准等问题,无法发挥数据资产价值。
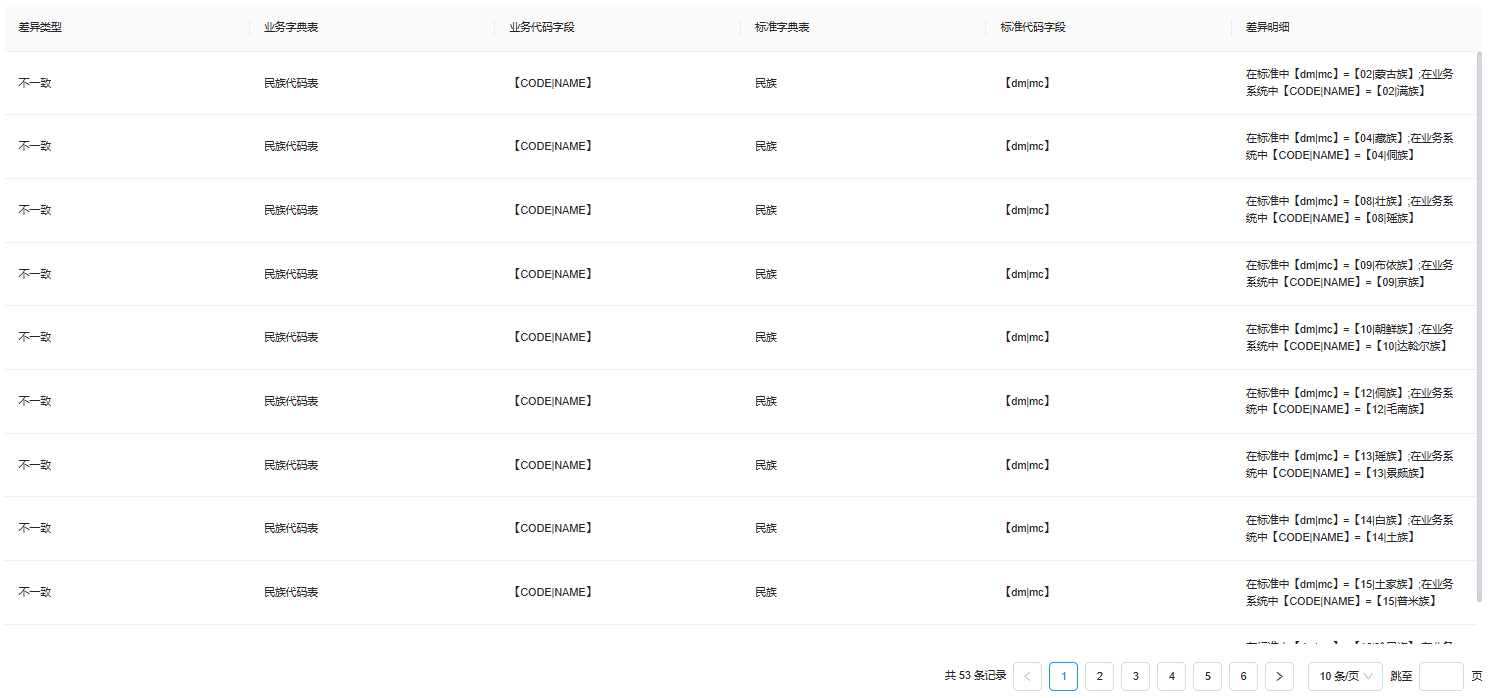
图4 数据中台检测到的代码差异
迪塔维V5解决方案升级了数据标准语义的“一键映射”能力,提供基于语义分析和机器学习算法的“智能对标转码进阶版”智能体。通过对源数据(业务代码)和目标数据(标准代码)的字段属性、业务属性的结构化解析,提取代码核心特征,并对代码语义进行深度挖掘匹配,实现自动对标。同时智能体内置了行业公认的代码对应关系规则库和迪塔维沉淀多年的转码经验库,可对匹配结果进行批量校验和修改,完成最优代码映射。
智能对标转码映射执行时会持续记录每次转码的过程和结果,结合人工干预的反馈数据,不断更新规则库和机器学习模型,持续提升算法的自适应能力和代码映射准确率。
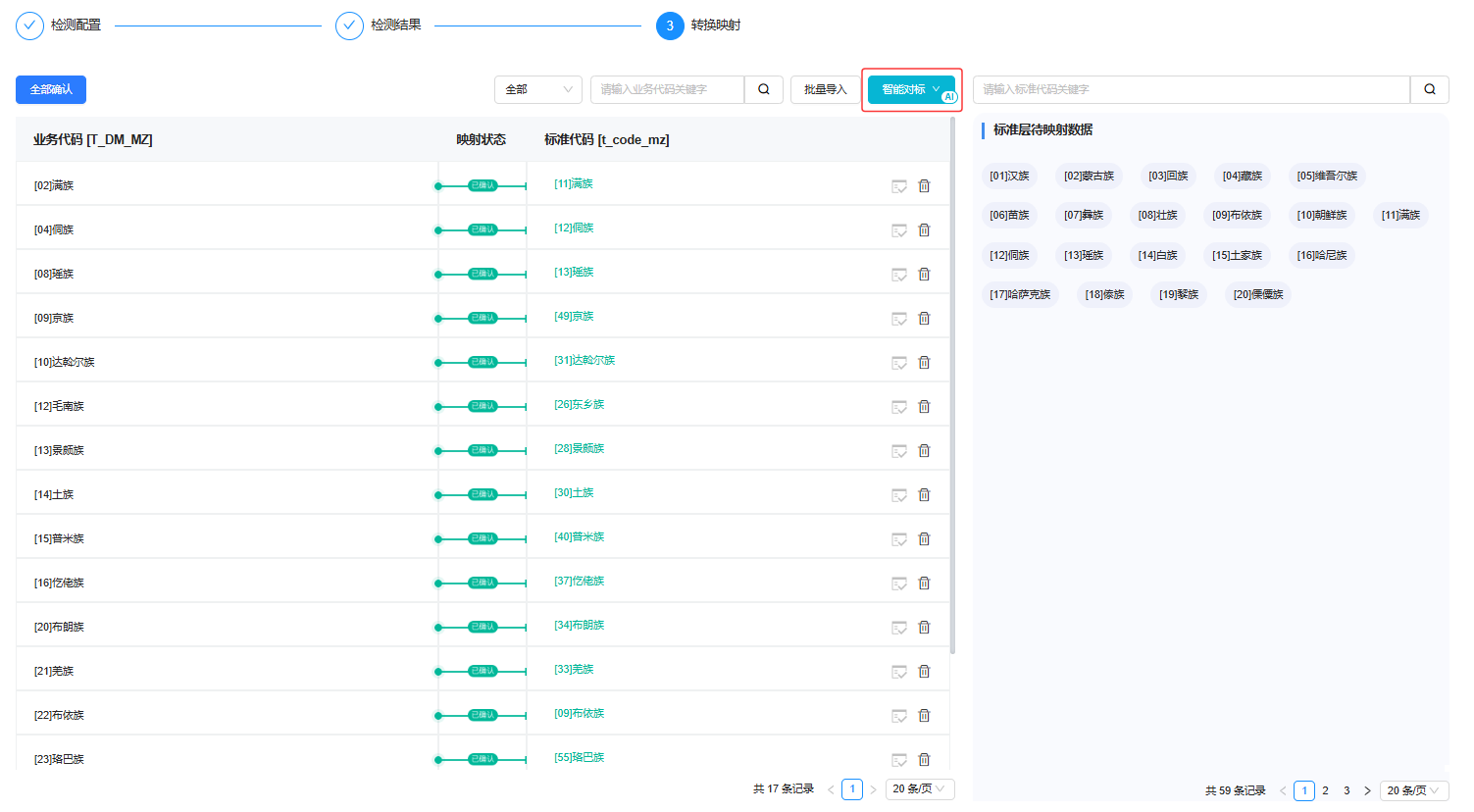
图5 对标转码智能映射结果
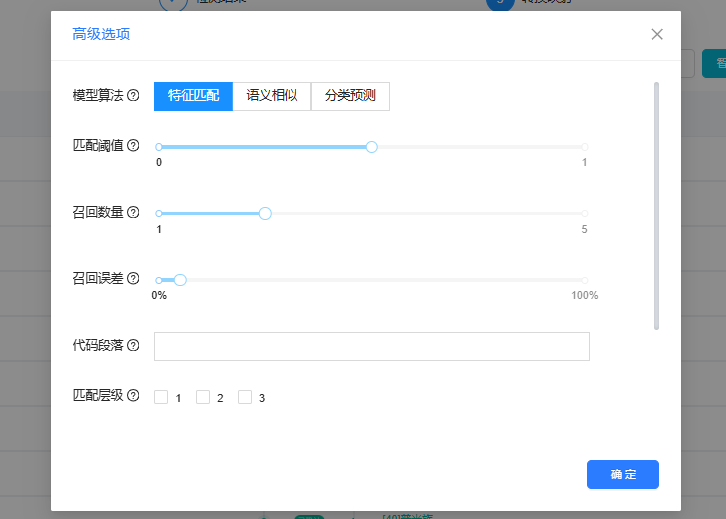
图6 智能对标转码映射算法设置
传统的转码映射工作需要人工逐条核对和处理,而迪塔维V5解决方案可一键自动识别映射关系并完善自校验过程,同时为人工干预提供了更加便捷的批量编辑页面,让转码业务处理效率实现质的飞跃。
结语
数据标准制定是数据治理的“核心”,代码标准一致是数据治理的“基石”,智能定标建模与对标转码服务融汇AI大模型能力,从处理效率、准确度、适应性等维度创新式重构了数据治理的业务处理方式,将传统人工处理转变为智能化实施能力,让数据治理工作更高效、更智能!更多场景,敬请期待——